Install ksqlDB by using Docker
ksqlDB and Docker containers¶
You can run ksqlDB locally by using Docker containers, and you can define a ksqlDB application by creating a stack of containers. A stack is a group of containers that run interrelated services. For more information on stacks, see Describing Apps Using Stack Files.
The minimal ksqlDB stack has containers for Apache Kafka®, ZooKeeper, and ksqlDB Server. More sophisticated ksqlDB stacks can have Schema Registry, Connect, and other third-party services, like Elasticsearch.
Stacks that have Schema Registry can use Avro- and Protobuf-encoded events in ksqlDB applications. Without Schema Registry, your ksqlDB applications can use only JSON or delimited formats.
Note
ksqlDB Server can connect to a remote Kafka cluster that isn't defined in a local stack. In this case, you can run ksqlDB in a standalone container and pass in the connection parameters on the command line.
Docker images for ksqlDB¶
ksqlDB has a server component and a separate command-line interface (CLI) component. Both components have their own Docker images.
Confluent maintains images on Docker Hub for ksqlDB components.
- ksqldb-server: ksqlDB Server image
- ksqldb-cli: ksqlDB command-line interface (CLI) image
- cp-zookeeper: ZooKeeper image (Community Version)
- cp-schema-registry: Schema Registry image (Community Version)
- cp-kafka: Apache Kafka® image (Community Version)
Install ksqlDB and Apache Kafka® by starting a Docker Compose stack that runs containers based on these images.
The following sections show how to install Docker and use the docker-compose tool to download and run the ksqlDB and related images.
Install Docker¶
Install the Docker distribution that's compatible with your operating system.
Important
For macOS and Windows, Docker runs in a virtual machine, and you must allocate at least 8 GB of RAM for the Docker VM to run the Kafka stack. The default is 2 GB.
- For macOS, use Docker Desktop for Mac. Change the Memory setting on the Resources page to 8 GB.
- For Windows, use Docker Desktop for Windows. No memory change is necessary when you run Docker on WSL 2.
- For Linux, follow the instructions for your Linux distribution. No memory change is necessary, because Docker runs natively and not in a VM.
Create a stack file to define your ksqlDB application¶
When you've decided on the services that you want in the stack, you define a
Compose file, or "stack" file,
which is a YAML file, to configure your ksqlDB application's services. The
stack file is frequently named docker-compose.yml.
To start the ksqlDB application, use the
docker-compose CLI to
run the stack for the application. Run docker-compose up to start the
application and docker-compose down to stop it.
Note
If the stack file is compatible with version 3 or higher,
you can use the docker stack deploy command:
docker stack deploy -c docker-compose.yml your-ksqldb-app.
For more information, see
docker stack deploy.
Build a ksqlDB application¶
The following steps describe how to define and deploy a stack for a ksqlDB application.
1. Define the services for your ksqlDB application¶
Decide which services you need for your ksqlDB application.
For a local installation, include one or more Kafka brokers in the stack and one or more ksqlDB Server instances.
- ZooKeeper: one instance, for cluster metadata
- Kafka: one or more instances
- Schema Registry: optional, but required for Avro, Protobuf, and JSON_SR
- ksqlDB Server: one or more instances
- ksqlDB CLI: optional
- Other services: like Elasticsearch, optional
Note
A stack that runs Schema Registry can handle Avro, Protobuf, and JSON_SR formats. Without Schema Registry, ksqlDB handles only JSON or delimited schemas for events.
You can declare a container for the ksqlDB CLI in the stack, or you can attach the CLI to a ksqlDB Server instance later, from a separate container.
2. Build the stack¶
Build a stack of services and deploy them by using Docker Compose.
Define the configuration of your local ksqlDB installation by creating a
Compose file, which by
convention is named docker-compose.yml.
3. Bring up the stack and run ksqlDB¶
To bring up the stack and run ksqlDB, use the
docker-compose tool,
which reads your docker-compose.yml file and runs containers for your
Kafka and ksqlDB services.
ksqlDB reference stack¶
Many docker-compose.yml files exist for different configurations, and this
topic shows a simple stack that you can extend for your use cases. The
ksqlDB reference stack
brings up these services:
- ZooKeeper: one instance
- Kafka: one broker
- Schema Registry: enables Avro, Protobuf, and JSON_SR
- ksqlDB Server: two instances
- ksqlDB CLI: one container running
/bin/sh
1. Clone the ksqlDB repository.¶
1 2 | |
2. Switch to the correct branch¶
Switch to the correct ksqlDB release branch.
1 | |
3. Start the stack¶
Start the stack by using the docker-compose up command. Depending on your
network speed, this may take up to 5-10 minutes.
1 | |
Tip
The -d option specifies detached mode, so containers run in the background.
Your output should resemble:
1 2 3 4 5 6 7 | |
Run the following command to check the status of the stack.
1 | |
Your output should resemble:
1 2 3 4 5 6 7 8 | |
When all of the containers have the Up state, the ksqlDB stack is ready
to use.
Start the ksqlDB CLI¶
When all of the services in the stack are Up, run the following command
to start the ksqlDB CLI and connect to a ksqlDB Server.
Run the following command to start the ksqlDB CLI in the running ksqldb-cli
container.
1 | |
After the ksqlDB CLI starts, your terminal should resemble the following.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
With the ksqlDB CLI running, you can issue SQL statements and queries on the
ksql> command line.
Note
The ksqlDB CLI connects to one ksqlDB Server at a time. The ksqlDB CLI doesn't support automatic failover to another ksqlDB Server.
Stacks with ksqlDB CLI containers¶
Some stacks declare a container for the ksqlDB CLI but don't specify the process that runs in the container. This kind of stack declares a generic shell entry point:
1 | |
To interact with a CLI container that's defined this way, use the
docker exec command to start the ksql process within the container.
1 | |
Run a ksqlDB CLI container¶
For stacks that don't declare a container for the ksqlDB CLI, use the
docker run command to start a new container from the ksqldb-cli
image.
1 2 3 | |
The --interactive and --tty options together enable the ksqlDB CLI process
to communicate with the console. For more information, see
docker run.
Stop your ksqlDB application¶
Run the following command to stop the containers in your stack.
1 | |
Your output should resemble:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Specify ksqlDB Server configuration parameters¶
You can specify the configuration for your ksqlDB Server instances by using these approaches:
- The
environmentkey: In the stack file, populate theenvironmentkey with your settings. By convention, the ksqlDB setting names are prepended withKSQL_. --envoption: On the docker run command line, specify your settings by using the--envoption once for each parameter. For more information, see Configure ksqlDB with Docker.- ksqlDB Server config file: Add settings to the
ksql-server.propertiesfile. This requires building your own Docker image for ksqlDB Server. For more information, see Configuring ksqlDB Server.
For a complete list of ksqlDB parameters, see the Configuration Parameter Reference.
You can also set any property for the Kafka Streams API, the Kafka producer, or the Kafka consumer.
A recommended approach is to configure a common set of properties using the ksqlDB Server configuration file and override specific properties as needed, using the environment variables.
ksqlDB must have access to a running Kafka cluster, which can be on
your local machine, in a data center, a public cloud, or Confluent Cloud.
For ksqlDB Server to connect to a Kafka cluster, the required
parameters are KSQL_LISTENERS and KSQL_BOOTSTRAP_SERVERS, which have the
following default values:
1 2 3 | |
ksqlDB runs separately from your Kafka cluster, so you specify the IP addresses of the cluster's bootstrap servers when you start a container for ksqlDB Server. For more information, see Configuring ksqlDB Server.
To start ksqlDB containers in different configurations, see Configure ksqlDB with Docker.
Supported versions and interoperability¶
You can use ksqlDB with compatible Apache Kafka® and Confluent Platform versions.
| ksqlDB version | 0.25.1 |
|---|---|
| Apache Kafka® version | 0.11.0 and later |
| Confluent Platform version | 5.5.0 and later |
ksqlDB supports Java 8 and Java 11.
Scale your ksqlDB Server deployment¶
You can scale ksqlDB by adding more capacity per server (vertically) or by adding more servers (horizontally). Also, you can scale ksqlDB clusters during live operations without loss of data. For more information, see Scaling ksqlDB.
The ksqlDB servers are run separately from the ksqlDB CLI client and Kafka brokers. You can deploy servers on remote machines, VMs, or containers, and the CLI connects to these remote servers.
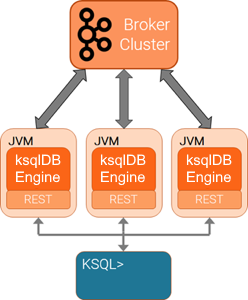
You can add or remove servers from the same resource pool during live operations, to scale query processing. You can use different resource pools to support workload isolation. For example, you could deploy separate pools for production and for testing.
Next Steps¶
Configure ksqlDB for Confluent Cloud¶
You can use ksqlDB with a Kafka cluster hosted in Confluent Cloud. For more information, see Connect ksqlDB to Confluent Cloud.
Experiment with other stacks¶
You can try out other stacks that have different configurations, like the "Quickstart" and "PostgreSQL" stacks.
ksqlDB Quickstart stack¶
Download the docker-compose.yml file from the Include Kafka tab of the
ksqlDB Quickstart.
This docker-compose.yml file defines a stack with these features:
- Start one ksqlDB Server instance.
- Does not start Schema Registry, so Avro and Protobuf schemas aren't available.
- Start the ksqlDB CLI container automatically.
Use the following command to start the ksqlDB CLI in the running ksqldb-cli
container.
1 | |
Full ksqlDB event processing application¶
The Confluent Platform Demo shows how to build an event streaming application that processes live edits to real Wikipedia pages. The docker-compose.yml file shows how to configure a stack with these features:
- Start a Kafka cluster with two brokers.
- Start a Connect instance.
- Start Schema Registry.
- Start containers running Elasticsearch and Kibana.
- Start ksqlDB Server and ksqlDB CLI containers.
Note
You must install Confluent Platform to run this application. The Confluent Platform images are distinct from the images that are used in this topic.
Confluent examples repo¶
There are numerous other stack files to explore in the Confluent examples repo.
Note
You must install Confluent Platform to run these applications. The Confluent Platform images are distinct from the images that are used in this topic.