Streaming ETL pipeline¶
What is it?¶
A streaming ETL pipeline, sometimes called a “streaming data pipeline”, is a set of software services that ingests events, transforms them, and loads them into destination storage systems. It’s often the case that you have data in one place and want to move it to another as soon as you receive it, but you need to make some changes to the data as you transfer it.
Maybe you need to do something simple, like transform the events to strip out any personally identifiable information. Sometimes, you may need to do something more complex, like enrich the events by joining them with data from another system. Or perhaps you want to pre-aggregate the events to reduce how much data you send to the downstream systems.
A streaming ETL pipeline enables streaming events between arbitrary sources and sinks, and it helps you make changes to the data while it’s in-flight.
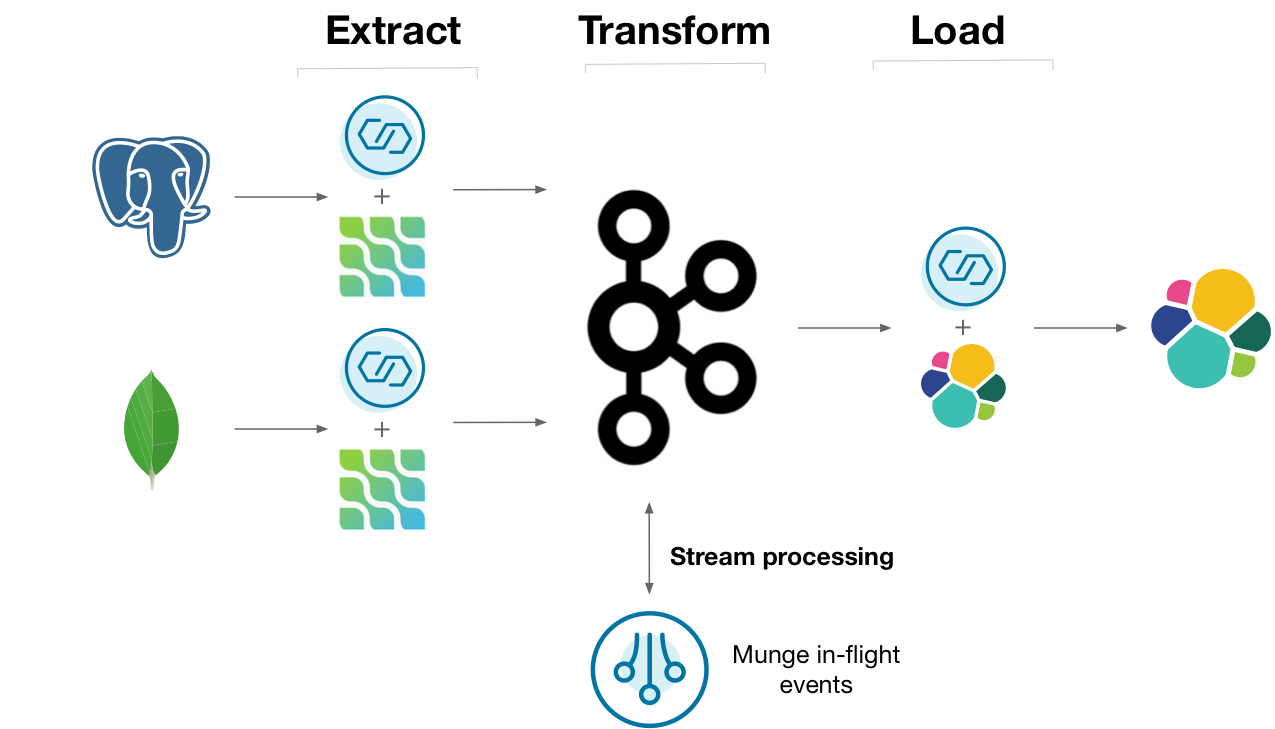
One way you might do this is to capture the changelogs of upstream Postgres and MongoDB databases using the Debezium Kafka connectors. The changelog can be stored in Kafka, where a series of deployed programs transforms, aggregates, and joins the data together. The processed data can be streamed out to ElasticSearch for indexing. Many people build this sort of architecture, but could it be made simpler?
Why ksqlDB?¶
Gluing all of the above services together is certainly a challenge. Along with your original databases and target analytical data store, you end up managing clusters for Kafka, connectors, and your stream processors. It's challenging to operate the entire stack as one.
ksqlDB helps streamline how you write and deploy streaming data pipelines by boiling it down to just two things: storage (Kafka) and compute (ksqlDB).
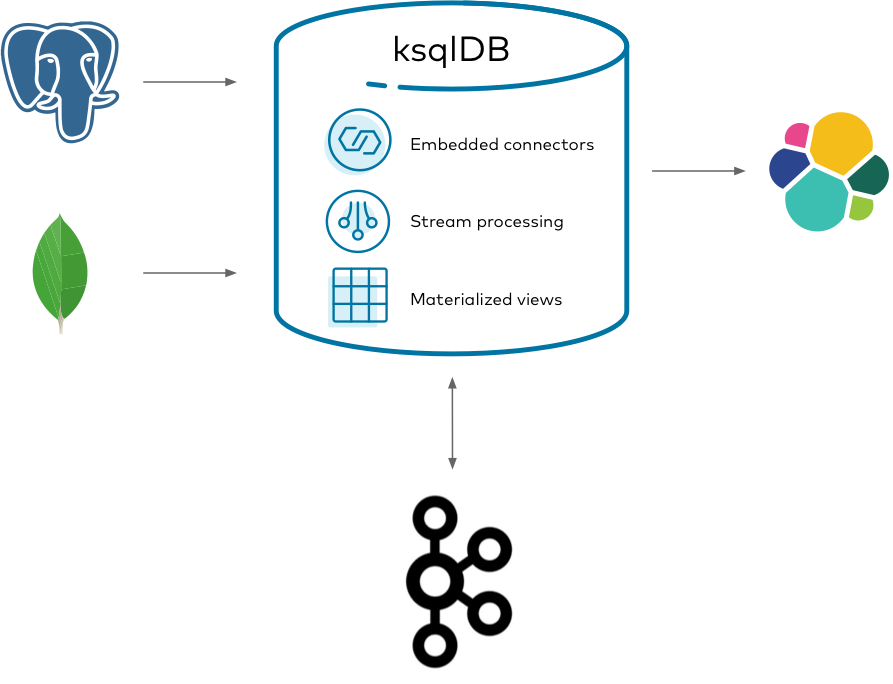
Using ksqlDB, you can run any Kafka Connect connector by embedding it in ksqlDB's servers. You can transform, join, and aggregate all of your streams together by using a coherent, powerful SQL language. This gives you a slender architecture for managing the end-to-end flow of your data pipeline.
Implement it¶
Suppose you work at a retail company that sells and ships orders to online customers. You want to analyze the shipment activity of orders as they happen in real-time. Because the company is somewhat large, the data for customers, orders, and shipments are spread across different databases and tables.
This tutorial shows how to create a streaming ETL pipeline that ingests and joins events together to create a cohesive view of orders that shipped. It demonstrates capturing changes from Postgres and MongoDB databases, forwarding them into Kafka, joining them together with ksqlDB, and sinking them out to ElasticSearch for analytics.
Get the connectors¶
To get started, download the connectors for Postgres, MongoDB, and Elasticsearch to a fresh directory. The easiest way to do this is by using confluent-hub.
Create a directory for your components:
1 | |
First, acquire the Postgres Debezium connector:
1 | |
Likewise for the MongoDB Debezium connector:
1 | |
And finally, the Elasticsearch connector:
1 | |
Start the stack¶
Next, set up and launch the services in the stack. But before you bring it up, you need to make a few changes to the way that Postgres launches so that it works well with Debezium. Debezium has dedicated documentation on this if you're interested, but this guide covers just the essentials. To simplify some of this, you launch a Postgres Docker container extended by Debezium to handle some of the customization. Also, you must create an additional configuration file at postgres/custom-config.conf with the following content:
1 2 3 4 | |
This sets up Postgres so that Debezium can watch for changes as they occur.
With the Postgres configuration file in place, create a docker-compose.yml file that defines the services to launch. You may need to increase the amount of memory that you give to Docker when you launch it:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 | |
There are a couple things to notice here. The Postgres image mounts the custom configuration file that you wrote. Postgres adds these configuration settings into its system-wide configuration. The environment variables you gave it also set up a blank database called customers, along with a user named postgres-user that can access it.
The compose file also sets up MongoDB as a replica set named my-replica-set. Debezium requires that MongoDB runs in this configuration to pick up changes from its oplog (see Debezium's documentation on MongoDB). In this case, you're just running a single-node replica set.
Finally, note that the ksqlDB server image mounts the confluent-hub-components directory, too. The jar files that you downloaded need to be on the classpath of ksqlDB when the server starts up.
Bring up the entire stack by running:
1 | |
Create the customers table in Postgres¶
It's pretty common for companies to keep their customer data in a relational database. You can model this information in a Postgres table. Start by logging into the container:
1 | |
Log into Postgres as the user created by default:
1 | |
Create a table that represents the customers. For simplicity, model a customer with three columns: an id, a name, and the age of the person:
1 | |
Seed the table with some initial data:
1 2 3 | |
Configure MongoDB for Debezium¶
Now that Postgres is set up, you can configure MongoDB. Start by logging into the container:
1 | |
Log into the Mongo console using the username specified in the Docker Compose file:
1 | |
Because MongoDB has been started as a replica set, it needs to be initiated. Run the following command to kick it off:
1 | |
Now that this node has become the primary in the replica set, you need to configure access so that Debezium can replicate changes remotely. Switch into the config database:
1 | |
Create a new role for Debezium. This role enables the user that you will create to access system-level collections, which are normally restricted:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Switch into the admin database and create the user here so that it can be authenticated:
1 | |
Create the user for Debezium. This user has root on the admin database, and can also access other databases needed for replication:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Create the logistics collections in MongoDB¶
With the user created, you can create the database for orders and shipments, which are stored as collections in a database called logistics:
1 | |
First create the orders:
1 | |
And likewise the shipments:
1 | |
Populate the orders collection with some initial data. Notice that the customer_id references identifiers that you created in your Postgres customers table:
1 2 3 4 5 | |
Do the same for shipments. Notice that the order_id references order ids you created in the previous collection.
1 2 3 4 5 | |
Start the Postgres and MongoDB Debezium source connectors¶
With all of the seed data in place, you can process it with ksqlDB. Connect to ksqlDB's server by using its interactive CLI. Run the following command from your host:
1 | |
Before you issue more commands, tell ksqlDB to start all queries from earliest point in each topic:
1 | |
Now you can ask Debezium to stream the Postgres changelog into Kafka. Invoke the following command in ksqlDB, which creates a Debezium source connector and writes all of its changes to Kafka topics:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Notice that this statement specifies an unwrap transform. By default, Debezium sends all events in an envelope that includes many pieces of information about the change captured. For this tutorial, the app only uses the value after it changed, so the command tells Kafka Connect to keep this information and discard the rest.
Run another source connector to ingest the changes from MongoDB. Specify the same behavior for discarding the Debezium envelope:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Create the ksqlDB source streams¶
For ksqlDB to be able to use the topics that Debezium created, you must declare streams over it. Because you configured Kafka Connect with Schema Registry, you don't need to declare the schema of the data for the streams, because it's inferred from the schema that Debezium writes with.
Run the following statement to create a stream over the customers table:
1 2 3 4 | |
Do the same for orders. For this stream, specify that the timestamp of the event is derived from the data itself. Specifically, it's extracted and parsed from the ts field.
1 2 3 4 5 6 | |
Finally, repeat the same for shipments:
1 2 3 4 5 6 | |
Join the streams together¶
The goal is to create a unified view of the activity of shipped orders. To do this, we want to include as much customer information on each shipment as possible. Recall that the orders collection that we created in MongoDB only had an identifier for each customer, but not their name. Use this identifier to look up the rest of the information by using a stream/table join. To do this, you must re-key the stream into a table by the id field:
1 2 3 4 5 6 7 | |
Now you can enrich the orders with more customer information. The following stream/table join creates a new stream that lifts the customer information into the order event:
1 2 3 4 5 6 7 8 9 10 11 | |
You can take this further by enriching all shipments with more information about the order and customer. Use a stream/stream join to find orders in the relevant window of time. This creates a new stream called shipped_orders that unifies the shipment, order, and customer information:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Start the Elasticsearch sink connector¶
The application must perform searches and analytics over this unified stream of information. To make this easy, spill the information out to Elasticsearch and run the following connector to sink the topic:
1 2 3 4 5 6 | |
Check that the data arrived in the index by running the following command from your host:
1 | |
Your output should resemble:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 | |
Try inserting more rows into Postgres and each MongoDB collection. Notice how the results update quickly in the Elasticsearch index.
Tear down the stack¶
When you're done, tear down the stack by running:
1 | |
Next steps¶
Want to learn more? Try another use case tutorial:
- Streaming ETL with Confluent: Routing and Fan-Out of Apache Kafka Messages with ksqlDB
- Materialized view/cache
- Event-driven microservice