This tutorial demonstrates a simple workflow using KSQL to write streaming queries against messages in Kafka.
To get started, you must start a Kafka cluster, including ZooKeeper and a Kafka broker. KSQL will then query messages from this Kafka cluster. KSQL is installed in the Confluent Platform by default.
Watch the screencast of Reading Kafka Data from KSQL on YouTube.
Prerequisites:
- Confluent Platform is installed and running. This installation includes a Kafka broker, KSQL, Control Center, ZooKeeper, Schema Registry, REST Proxy, and Connect.
- If you installed Confluent Platform via TAR or ZIP, navigate into the installation directory. The paths and commands used throughout this tutorial assume that you are in this installation directory.
- Consider installing the Confluent CLI to start a local installation of Confluent Platform.
- Java: Minimum version 1.8. Install Oracle Java JRE or JDK >= 1.8 on your local machine
Create Topics and Produce Data¶
Create and produce data to the Kafka topics pageviews and users.
These steps use the KSQL datagen that is included Confluent Platform.
-
Create the
pageviewstopic and produce data using the data generator. The following example continuously generates data with a value in DELIMITED format.bash <path-to-confluent>/bin/ksql-datagen quickstart=pageviews format=delimited topic=pageviews msgRate=5 -
Produce Kafka data to the
userstopic using the data generator. The following example continuously generates data with a value in JSON format.bash <path-to-confluent>/bin/ksql-datagen quickstart=users format=avro topic=users msgRate=1
Tip
You can also produce Kafka data using the kafka-console-producer CLI
provided with Confluent Platform.
Launch the KSQL CLI¶
To launch the CLI, run the following command. It will route the CLI logs
to the ./ksql_logs directory, relative to your current directory. By
default, the CLI will look for a KSQL Server running at
http://localhost:8088.
1 | |
Important
By default KSQL attempts to store its logs in a directory called logs
that is relative to the location of the ksql executable. For example,
if ksql is installed at /usr/local/bin/ksql, then it would attempt
to store its logs in /usr/local/logs. If you are running ksql from
the default Confluent Platform location, <path-to-confluent>/bin, you must
override this default behavior by using the LOG_DIR variable.
After KSQL is started, your terminal should resemble this.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Inspect Kafka Topics By Using SHOW and PRINT Statements¶
KSQL enables inspecting Kafka topics and messages in real time.
- Use the SHOW TOPICS statement to list the available topics in the Kafka cluster.
- Use the PRINT statement to see a topic's messages as they arrive.
In the KSQL CLI, run the following statement:
1 | |
Your output should resemble:
1 2 3 4 5 6 | |
By default, KSQL hides internal and system topics. Use the SHOW ALL TOPICS statement to see the full list of topics in the Kafka cluster:
1 | |
Your output should resemble:
1 2 3 4 5 6 7 8 9 10 | |
Inspect the users topic by using the PRINT statement:
1 | |
Note
The PRINT statement is one of the few case-sensitive commands in ksqlDB, even when the topic name is not quoted.
Your output should resemble:
1 2 3 4 5 6 7 | |
Press Ctrl+C to stop printing messages.
Inspect the pageviews topic by using the PRINT statement:
1 | |
Your output should resemble:
1 2 3 4 5 6 7 | |
Press Ctrl+C to stop printing messages.
For more information, see KSQL Syntax Reference.
Create a Stream and Table¶
These examples query messages from Kafka topics called pageviews and
users using the following schemas:
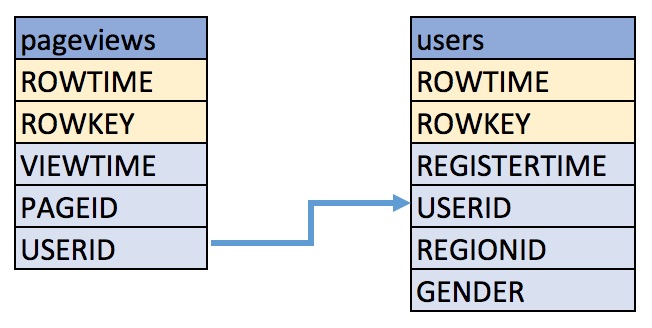
-
Create a stream, named
pageviews_original, from thepageviewsKafka topic, specifying thevalue_formatofDELIMITED.sql CREATE STREAM pageviews_original (rowkey bigint key, viewtime bigint, userid varchar, pageid varchar) WITH (kafka_topic='pageviews', value_format='DELIMITED');Your output should resemble:
``` Message
Stream created¶
```
Tip
You can run
DESCRIBE pageviews_original;to see the schema for the stream. Notice that ksqlDB created an additional column, namedROWTIME, which corresponds with the Kafka message timestamp. -
Create a table, named
users_original, from theusersKafka topic, specifying thevalue_formatofAVRO.sql CREATE TABLE users_original WITH (kafka_topic='users', value_format='AVRO', key = 'userid');Your output should resemble:
``` Message
Table created¶
```
Note
You may have noticed the CREATE TABLE did not define the set of columns like the CREATE STREAM statement did. This is because the value format is Avro, and the DataGen tool publishes the Avro schema to Schema Registry. ksqlDB retrieves the schema from Schema Registry and uses this to build the SQL schema for the table. You may still provide the schema if you wish. Until Github issue #4462 is complete, schema inference is only available for the value columns. By default, it is assumed the key schema is a single
KAFKAformattedSTRINGcolumn and is calledROWKEY. It is also possible to supply just the key column in the statement, allowing you to specify the key column type. For example:CREATE TABLE users_original (ROWKEY INT KEY) WITH (...);Note
The data generated has the same value in the Kafka record's key as the
userIdfield in the value. Specifyingkey='userId'in the WITH clause above lets ksqlDB know this. ksqlDB uses this information to allow joins against the table to use the more descriptiveuserIdcolumn name, rather thanROWKEY. Joining on either yields the same results. If your data doesn't contain a copy of the key in the value, you can join onROWKEY.Tip
You can run
DESCRIBE users_original;to see the schema for the Table. -
Optional: Show all streams and tables. ``` ksql> SHOW STREAMS;
Stream Name | Kafka Topic | Format¶
KSQL_PROCESSING_LOG | default_ksql_processing_log | JSON
PAGEVIEWS_ORIGINAL | pageviews | DELIMITED
ksql> SHOW TABLES;
Table Name | Kafka Topic | Format | Windowed¶
USERS_ORIGINAL | users | AVRO | false¶
```
Tip
Notice the KSQL_PROCESSING_LOG stream listed in the SHOW STREAMS
output? ksqlDB appends messages that describe any issues it
encountered while processing your data. If things aren't working
as you expect, check the contents of this stream
to see if ksqlDB is encountering data errors.
Viewing your data¶
- Use
SELECTto create a query that returns data from a TABLE. This query includes theLIMITkeyword to limit the number of rows returned in the query result, and theEMIT CHANGESkeywords to indicate we wish to stream results back. This is known as a pull query. See the queries for an explanation of the different query types. Note that exact data output may vary because of the randomness of the data generation.sql SELECT * from users_original emit changes limit 5;
Your output should resemble:
+--------------------+--------------+--------------+---------+----------+-------------+
|ROWTIME |ROWKEY |REGISTERTIME |GENDER |REGIONID |USERID |
+--------------------+--------------+--------------+---------+----------+-------------+
|1581077558655 |User_9 |1513529638461 |OTHER |Region_1 |User_9 |
|1581077561454 |User_7 |1489408314958 |OTHER |Region_2 |User_7 |
|1581077561654 |User_3 |1511291005264 |MALE |Region_2 |User_3 |
|1581077561857 |User_4 |1496797956753 |OTHER |Region_1 |User_4 |
|1581077562858 |User_8 |1489169082491 |FEMALE |Region_8 |User_8 |
Limit Reached
Query terminated
!!! note
Push queries on tables will output the full history of the table that is stored
in the Kafka changelog topic, i.e. it will output historic data, followed by the
stream of updates to the table. It is therefore likely that rows with matching
ROWKEY are output as existing rows in the table are updated.
- View the data in your pageviews_original stream by issuing the following
push query:
sql SELECT viewtime, userid, pageid FROM pageviews_original emit changes LIMIT 3;
Your output should resemble:
+--------------+--------------+--------------+
|VIEWTIME |USERID |PAGEID |
+--------------+--------------+--------------+
|1581078296791 |User_1 |Page_54 |
|1581078297792 |User_8 |Page_93 |
|1581078298792 |User_6 |Page_26 |
Limit Reached
Query terminated
!!! note
By default, push queries on streams only output changes that occur
after the query is started, i.e. historic data is not included.
Run set 'auto.offset.reset'='earliest'; to update your session
properties if you want to see the historic data.
Write Queries¶
These examples write queries using KSQL.
-
Create query that enriches the pageviews data with the user's gender and regionid from the users table. The following query enriches the
pageviews_originalSTREAM by doing aLEFT JOINwith theusers_originalTABLE on the userid column.sql SELECT users_original.userid AS userid, pageid, regionid, gender FROM pageviews_original LEFT JOIN users_original ON pageviews_original.userid = users_original.userid EMIT CHANGES LIMIT 5;Your output should resemble:
+-------------------+-------------------+-------------------+-------------------+ |USERID |PAGEID |REGIONID |GENDER | +-------------------+-------------------+-------------------+-------------------+ |User_7 |Page_23 |Region_2 |OTHER | |User_3 |Page_42 |Region_2 |MALE | |User_7 |Page_87 |Region_2 |OTHER | |User_2 |Page_57 |Region_5 |FEMALE | |User_9 |Page_59 |Region_1 |OTHER | Limit Reached Query terminatedNote
The join to the users table is on the userid column, which was identified as an alias for the tables primary key,
ROWKEY, in the CREATE TABLE statement.userIdandROWKEYcan be used interchangeably as the join criteria for the table. However, the data inuseridon the stream side does not match the stream's key. Hence, ksqlDB will first internally repartition the stream by theuserIdcolumn. -
Create a persistent query by using the
CREATE STREAMkeywords to precede theSELECTstatement, and removing theLIMITclause. The results from this query are written to thePAGEVIEWS_ENRICHEDKafka topic.sql CREATE STREAM pageviews_enriched AS SELECT users_original.userid AS userid, pageid, regionid, gender FROM pageviews_original LEFT JOIN users_original ON pageviews_original.userid = users_original.userid EMIT CHANGES;Your output should resemble:
``` Message
Stream PAGEVIEWS_ENRICHED created and running. Created by query with query ID: CSAS_PAGEVIEWS_ENRICHED_0¶
```
Tip
You can run
DESCRIBE pageviews_enriched;to describe the stream. -
Use
SELECTto view query results as they come in. To stop viewing the query results, press Ctrl-C. This stops printing to the console but it does not terminate the actual query. The query continues to run in the underlying KSQL application.sql SELECT * FROM pageviews_enriched emit changes;Your output should resemble:
``` +-------------+------------+------------+------------+------------+------------+ |ROWTIME |ROWKEY |USERID |PAGEID |REGIONID |GENDER | +-------------+------------+------------+------------+------------+------------+ |1581079706741|User_5 |User_5 |Page_53 |Region_3 |FEMALE | |1581079707742|User_2 |User_2 |Page_86 |Region_5 |OTHER | |1581079708745|User_9 |User_9 |Page_75 |Region_1 |OTHER |
^CQuery terminated ```
Use CTRL+C to terminate the query.
-
Create a new persistent query where a condition limits the streams content, using
WHERE. Results from this query are written to a Kafka topic calledPAGEVIEWS_FEMALE.sql CREATE STREAM pageviews_female AS SELECT * FROM pageviews_enriched WHERE gender = 'FEMALE' EMIT CHANGES;Your output should resemble:
``` Message
Stream PAGEVIEWS_FEMALE created and running. Created by query with query ID: CSAS_PAGEVIEWS_FEMALE_11¶
```
Tip
You can run
DESCRIBE pageviews_female;to describe the stream. -
Create a new persistent query where another condition is met, using
LIKE. Results from this query are written to thepageviews_enriched_r8_r9Kafka topic.sql CREATE STREAM pageviews_female_like_89 WITH (kafka_topic='pageviews_enriched_r8_r9') AS SELECT * FROM pageviews_female WHERE regionid LIKE '%_8' OR regionid LIKE '%_9' EMIT CHANGES;Your output should resemble:
``` Message
Stream PAGEVIEWS_FEMALE_LIKE_89 created and running. Created by query with query ID: CSAS_PAGEVIEWS_FEMALE_LIKE_89_13¶
```
-
Create a new persistent query that counts the pageviews for each region and gender combination in a tumbling window of 30 seconds when the count is greater than one. Results from this query are written to the
PAGEVIEWS_REGIONSKafka topic in the Avro format. KSQL will register the Avro schema with the configured Schema Registry when it writes the first message to thePAGEVIEWS_REGIONStopic.sql CREATE TABLE pageviews_regions WITH (VALUE_FORMAT='avro') AS SELECT gender, regionid , COUNT(*) AS numusers FROM pageviews_enriched WINDOW TUMBLING (size 30 second) GROUP BY gender, regionid EMIT CHANGES;Your output should resemble:
``` Message
Table PAGEVIEWS_REGIONS created and running. Created by query with query ID: CTAS_PAGEVIEWS_REGIONS_15¶
```
Tip
You can run
DESCRIBE pageviews_regions;to describe the table. -
Optional: View results from the above queries using push query.
sql SELECT * FROM pageviews_regions EMIT CHANGES LIMIT 5;Your output should resemble:
+---------------+-----------------+---------------+---------------+---------------+---------------+---------------+ |ROWTIME |ROWKEY |WINDOWSTART |WINDOWEND |GENDER |REGIONID |NUMUSERS | +---------------+-----------------+---------------+---------------+---------------+---------------+---------------+ |1581080500530 |OTHER|+|Region_9 |1581080490000 |1581080520000 |OTHER |Region_9 |1 | |1581080501530 |OTHER|+|Region_5 |1581080490000 |1581080520000 |OTHER |Region_5 |2 | |1581080510532 |MALE|+|Region_7 |1581080490000 |1581080520000 |MALE |Region_7 |4 | |1581080513532 |FEMALE|+|Region_1|1581080490000 |1581080520000 |FEMALE |Region_1 |2 | |1581080516533 |MALE|+|Region_2 |1581080490000 |1581080520000 |MALE |Region_2 |3 | Limit Reached Query terminatedNote
Notice the addition of the WINDOWSTART and WINDOWEND columns. These are available because
pageviews_regionsis aggregating data per 30 second window. ksqlDB automatically adds these system columns for windowed results. -
Optional: View results from the above queries using pull query
When a CREATE TABLE statement contains a GROUP BY clause, ksqlDB is internally building an table containing the results of the aggregation. ksqlDB supports pull queries against such aggregation results.
Unlike the push query used in the previous step, which pushes a stream of results to you, pull queries pull a result set and automatically terminate.
Push queries do not have the
EMIT CHANGESclause.View all the windows and user counts available for a specific gender and region using a pull query:
sql SELECT * FROM pageviews_regions WHERE ROWKEY='OTHER|+|Region_9';Your output should resemble:
+------------------+------------------+------------------+------------------+------------------+------------------+------------------+ |ROWKEY |WINDOWSTART |WINDOWEND |ROWTIME |GENDER |REGIONID |NUMUSERS | +------------------+------------------+------------------+------------------+------------------+------------------+------------------+ |OTHER|+|Region_9 |1581080490000 |1581080520000 |1581080500530 |OTHER |Region_9 |1 | |OTHER|+|Region_9 |1581080550000 |1581080580000 |1581080576526 |OTHER |Region_9 |4 | |OTHER|+|Region_9 |1581080580000 |1581080610000 |1581080606525 |OTHER |Region_9 |4 | |OTHER|+|Region_9 |1581080610000 |1581080640000 |1581080622524 |OTHER |Region_9 |3 | |OTHER|+|Region_9 |1581080640000 |1581080670000 |1581080667528 |OTHER |Region_9 |6 | ...Pull queries on windowed tables such as pageviews_regions also supports querying a single window's result:
sql SELECT NUMUSERS FROM pageviews_regions WHERE ROWKEY='OTHER|+|Region_9' AND WINDOWSTART=1581080550000;Important
You will need to change value of
WINDOWSTARTin the above SQL to match one of the window boundaries in your data. Otherwise no results will be returned.Your output should resemble:
+----------+ |NUMUSERS | +----------+ |4 | Query terminatedOr querying a range of windows:
sql SELECT WINDOWSTART, WINDOWEND, NUMUSERS FROM pageviews_regions WHERE ROWKEY='OTHER|+|Region_9' AND 1581080550000 <= WINDOWSTART AND WINDOWSTART <= 1581080610000;Important
You will need to change value of
WINDOWSTARTin the above SQL to match one of the window boundaries in your data. Otherwise no results will be returned.Your output should resemble:
+----------------------------+----------------------------+----------------------------+ |WINDOWSTART |WINDOWEND |NUMUSERS | +----------------------------+----------------------------+----------------------------+ |1581080550000 |1581080580000 |4 | |1581080580000 |1581080610000 |4 | |1581080610000 |1581080640000 |3 | Query terminated -
Optional: Show all persistent queries.
sql SHOW QUERIES;Your output should resemble:
``` Query ID | Status | Sink Name | Sink Kafka Topic | Query String
CTAS_PAGEVIEWS_REGIONS_15 | RUNNING | PAGEVIEWS_REGIONS | PAGEVIEWS_REGIONS | CREATE TABLE PAGEVIEWS_REGIONS WITH (KAFKA_TOPIC='PAGEVIEWS_REGIONS', PARTITIONS=1, REPLICAS=1, VALUE_FORMAT='avro') AS SELECT PAGEVIEWS_ENRICHED.GENDER GENDER, PAGEVIEWS_ENRICHED.REGIONID REGIONID, COUNT() NUMUSERSFROM PAGEVIEWS_ENRICHED PAGEVIEWS_ENRICHEDWINDOW TUMBLING ( SIZE 30 SECONDS ) GROUP BY PAGEVIEWS_ENRICHED.GENDER, PAGEVIEWS_ENRICHED.REGIONIDEMIT CHANGES;
CSAS_PAGEVIEWS_FEMALE_LIKE_89_13 | RUNNING | PAGEVIEWS_FEMALE_LIKE_89 | pageviews_enriched_r8_r9 | CREATE STREAM PAGEVIEWS_FEMALE_LIKE_89 WITH (KAFKA_TOPIC='pageviews_enriched_r8_r9', PARTITIONS=1, REPLICAS=1) AS SELECT FROM PAGEVIEWS_FEMALE PAGEVIEWS_FEMALEWHERE ((PAGEVIEWS_FEMALE.REGIONID LIKE '%_8') OR (PAGEVIEWS_FEMALE.REGIONID LIKE '%_9'))EMIT CHANGES;
CSAS_PAGEVIEWS_ENRICHED_0 | RUNNING | PAGEVIEWS_ENRICHED | PAGEVIEWS_ENRICHED | CREATE STREAM PAGEVIEWS_ENRICHED WITH (KAFKA_TOPIC='PAGEVIEWS_ENRICHED', PARTITIONS=1, REPLICAS=1) AS SELECT USERS_ORIGINAL.USERID USERID, PAGEVIEWS_ORIGINAL.PAGEID PAGEID, USERS_ORIGINAL.REGIONID REGIONID, USERS_ORIGINAL.GENDER GENDERFROM PAGEVIEWS_ORIGINAL PAGEVIEWS_ORIGINALLEFT OUTER JOIN USERS_ORIGINAL USERS_ORIGINAL ON ((PAGEVIEWS_ORIGINAL.USERID = USERS_ORIGINAL.USERID))EMIT CHANGES; CSAS_PAGEVIEWS_FEMALE_11 | RUNNING | PAGEVIEWS_FEMALE | PAGEVIEWS_FEMALE | CREATE STREAM PAGEVIEWS_FEMALE WITH (KAFKA_TOPIC='PAGEVIEWS_FEMALE', PARTITIONS=1, REPLICAS=1) AS SELECT *FROM PAGEVIEWS_ENRICHED PAGEVIEWS_ENRICHEDWHERE (PAGEVIEWS_ENRICHED.GENDER = 'FEMALE')EMIT CHANGES;For detailed information on a Query run: EXPLAIN
; ``` -
Optional: Examine query run-time metrics and details. Observe that information including the target Kafka topic is available, as well as throughput figures for the messages being processed.
sql DESCRIBE EXTENDED PAGEVIEWS_REGIONS;Your output should resemble:
``` Name : PAGEVIEWS_REGIONS Type : TABLE Key field : Timestamp field : Not set - using
Key format : KAFKA Value format : AVRO Kafka topic : PAGEVIEWS_REGIONS (partitions: 1, replication: 1) Statement : CREATE TABLE PAGEVIEWS_REGIONS WITH (KAFKA_TOPIC='PAGEVIEWS_REGIONS', PARTITIONS=1, REPLICAS=1, VALUE_FORMAT='json') AS SELECT PAGEVIEWS_ENRICHED.GENDER GENDER, PAGEVIEWS_ENRICHED.REGIONID REGIONID, COUNT(*) NUMUSERS FROM PAGEVIEWS_ENRICHED PAGEVIEWS_ENRICHED WINDOW TUMBLING ( SIZE 30 SECONDS ) GROUP BY PAGEVIEWS_ENRICHED.GENDER, PAGEVIEWS_ENRICHED.REGIONID EMIT CHANGES; Field | Type¶
ROWTIME | BIGINT (system)
ROWKEY | VARCHAR(STRING) (system) (Window type: TUMBLING) GENDER | VARCHAR(STRING)
REGIONID | VARCHAR(STRING)
NUMUSERS | BIGINT
Queries that write from this TABLE¶
CTAS_PAGEVIEWS_REGIONS_15 (RUNNING) : CREATE TABLE PAGEVIEWS_REGIONS WITH (KAFKA_TOPIC='PAGEVIEWS_REGIONS', PARTITIONS=1, REPLICAS=1, VALUE_FORMAT='json') AS SELECT PAGEVIEWS_ENRICHED.GENDER GENDER, PAGEVIEWS_ENRICHED.REGIONID REGIONID, COUNT(*) NUMUSERSFROM PAGEVIEWS_ENRICHED PAGEVIEWS_ENRICHEDWINDOW TUMBLING ( SIZE 30 SECONDS ) GROUP BY PAGEVIEWS_ENRICHED.GENDER, PAGEVIEWS_ENRICHED.REGIONIDEMIT CHANGES;
For query topology and execution plan please run: EXPLAIN
Local runtime statistics¶
messages-per-sec: 0.90 total-messages: 498 last-message: 2020-02-07T13:10:32.033Z ```
Using Nested Schemas (STRUCT) in KSQL¶
Struct support enables the modeling and access of nested data in Kafka topics, from both JSON and Avro.
In this section, you use the ksql-datagen tool to create some sample data
that includes a nested address field. Run this in a new window, and leave
it running.
1 2 3 4 5 | |
From the KSQL command prompt, register the topic in KSQL:
1 2 3 4 5 6 7 8 9 10 | |
Your output should resemble:
1 2 3 4 | |
Use the DESCRIBE function to observe the schema, which includes a
STRUCT:
1 | |
Your output should resemble:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Query the data, using -> notation to access the Struct contents:
1 | |
Your output should resemble:
1 2 3 4 5 6 7 8 9 10 | |
Stream-Stream join¶
Using a stream-stream join, it is possible to join two event streams on a common key. An example of this could be a stream of order events and a stream of shipment events. By joining these on the order key, you can see shipment information alongside the order.
In the ksqlDB CLI create two new streams, both streams will store their order id in ROWKEY:
1 2 3 4 5 | |
Note
ksqlDB will create the underlying topics in Kafka when these statements
are executed. You can also specify the REPLICAS count.
After both CREATE STREAM statements, your output should resemble:
1 2 3 4 | |
Populate the streams with some sample data using the INSERT VALUES statement:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Query the data to confirm that it's present in the topics.
Tip
Run the following to tell KSQL to read from the beginning of each stream:
sql
SET 'auto.offset.reset' = 'earliest';
You can skip this if you have already run it within your current
KSQL CLI session.
For the NEW_ORDERS topic, run:
1 | |
Your output should resemble:
1 2 3 4 5 6 7 8 | |
For the SHIPMENTS topic, run:
1 | |
Your output should resemble:
1 2 3 4 5 6 7 | |
Run the following query, which will show orders with associated shipments, based on a join window of 1 hour.
1 2 3 4 5 6 7 | |
Your output should resemble:
1 2 3 4 5 | |
Note that message with ORDER_ID=2 has no corresponding SHIPMENT_ID
or WAREHOUSE - this is because there is no corresponding row on the
shipments stream within the time window specified.
Start the ksqlDB CLI in a second window by running:
1 | |
Enter the following INSERT VALUES statement to insert the shipment for order id 2:
1 | |
Switching back to your primary ksqlDB CLI window, notice that a third row has now been output:
1 2 3 4 5 6 | |
Press Ctrl+C to cancel the SELECT query and return to the KSQL prompt.
Table-Table join¶
Using a table-table join, it is possible to join two tables of on a common key. KSQL tables provide the latest value for a given key. They can only be joined on the key, and one-to-many (1:N) joins are not supported in the current semantic model.
In this example we have location data about a warehouse from one system, being enriched with data about the size of the warehouse from another.
In the KSQL CLI, register both topics as KSQL tables. Note, in this example the warehouse id is stored both in the key and in the WAREHOUSE_ID field in the value:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
After both CREATE TABLE statements, your output should resemble:
1 2 3 4 | |
In the KSQL CLI, insert sample data into the tables:
1 2 3 4 5 6 7 8 | |
Check both tables that the message key (ROWKEY) matches the declared
key (WAREHOUSE_ID) - the output should show that they are equal. If
they were not, the join will not succeed or behave as expected.
Inspect the WAREHOUSE_LOCATION table:
1 | |
Your output should resemble:
1 2 3 4 5 6 7 8 | |
Inspect the WAREHOUSE_SIZE table:
1 | |
Your output should resemble:
1 2 3 4 5 6 7 8 | |
Now join the two tables:
1 2 3 4 5 6 | |
Your output should resemble:
1 2 3 4 5 6 7 8 | |
INSERT INTO¶
The INSERT INTO syntax can be used to merge the contents of multiple
streams. An example of this could be where the same event type is coming
from different sources.
Run two datagen processes, each writing to a different topic, simulating order data arriving from a local installation vs from a third-party: :::
Tip
Each of these commands should be run in a separate window. When the exercise is finished, exit them by pressing Ctrl-C.
1 2 3 4 5 6 7 8 9 10 11 | |
In KSQL, register the source topic for each:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
After each CREATE STREAM statement you should get the message:
1 2 3 4 | |
Create the output stream, using the standard CREATE STREAM … AS
syntax. Because multiple sources of data are being joined into a common
target, it is useful to add in lineage information. This can be done by
simply including it as part of the SELECT:
1 | |
Your output should resemble:
1 2 3 4 | |
Use the DESCRIBE command to observe the schema of the target stream.
1 | |
Your output should resemble:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Add stream of 3rd party orders into the existing output stream:
1 | |
Your output should resemble:
1 2 3 4 | |
Query the output stream to verify that data from each source is being written to it:
1 | |
Your output should resemble the following. Note that there are messages
from both source topics (denoted by LOCAL and 3RD PARTY
respectively).
1 2 3 4 5 6 7 | |
Press Ctrl+C to cancel the SELECT query and return to the KSQL prompt.
You can view the two queries that are running using SHOW QUERIES:
1 | |
Your output should resemble:
1 2 3 4 5 | |
Terminate and Exit¶
KSQL¶
Important
Persisted queries will continuously run as KSQL applications until they are manually terminated. Exiting KSQL CLI does not terminate persistent queries.
-
From the output of
SHOW QUERIES;identify a query ID you would like to terminate. For example, if you wish to terminate query IDCTAS_PAGEVIEWS_REGIONS_15:sql TERMINATE CTAS_PAGEVIEWS_REGIONS_15;Tip
The actual name of the query running may vary; refer to the output of
SHOW QUERIES;. -
Run the
exitcommand to leave the KSQL CLI.ksql> exit Exiting ksqlDB.
Confluent CLI¶
If you are running Confluent Platform using the CLI, you can stop it with this command.
1 | |
Page last revised on: 2020-04-29