Architecture
You can use ksqlDB to build event streaming applications from Apache Kafka® topics by using only SQL statements and queries. ksqlDB is built on Kafka Streams, so a ksqlDB application communicates with a Kafka cluster like any other Kafka Streams application.
ksqlDB Components¶
ksqlDB has these main components:
- ksqlDB engine -- processes SQL statements and queries
- REST interface -- enables client access to the engine
- ksqlDB CLI -- console that provides a command-line interface (CLI) to the engine
- ksqlDB UI -- enables developing ksqlDB applications in Confluent Control Center and Confluent Cloud
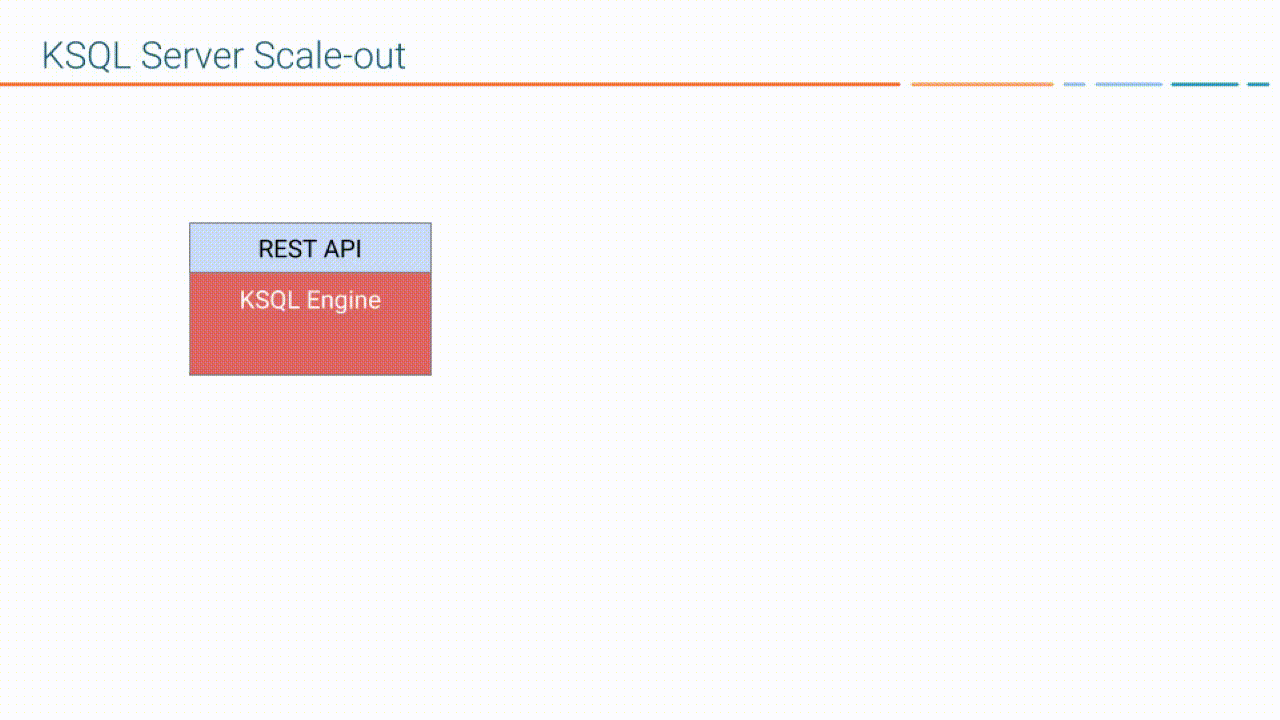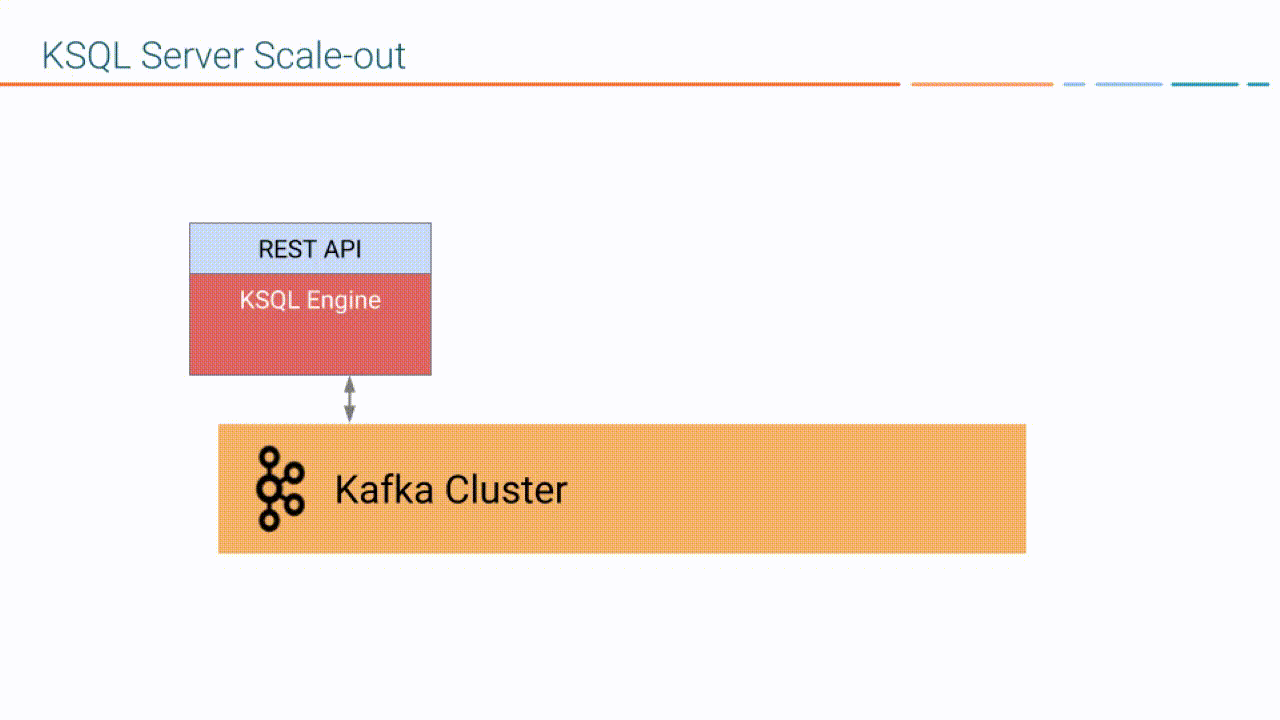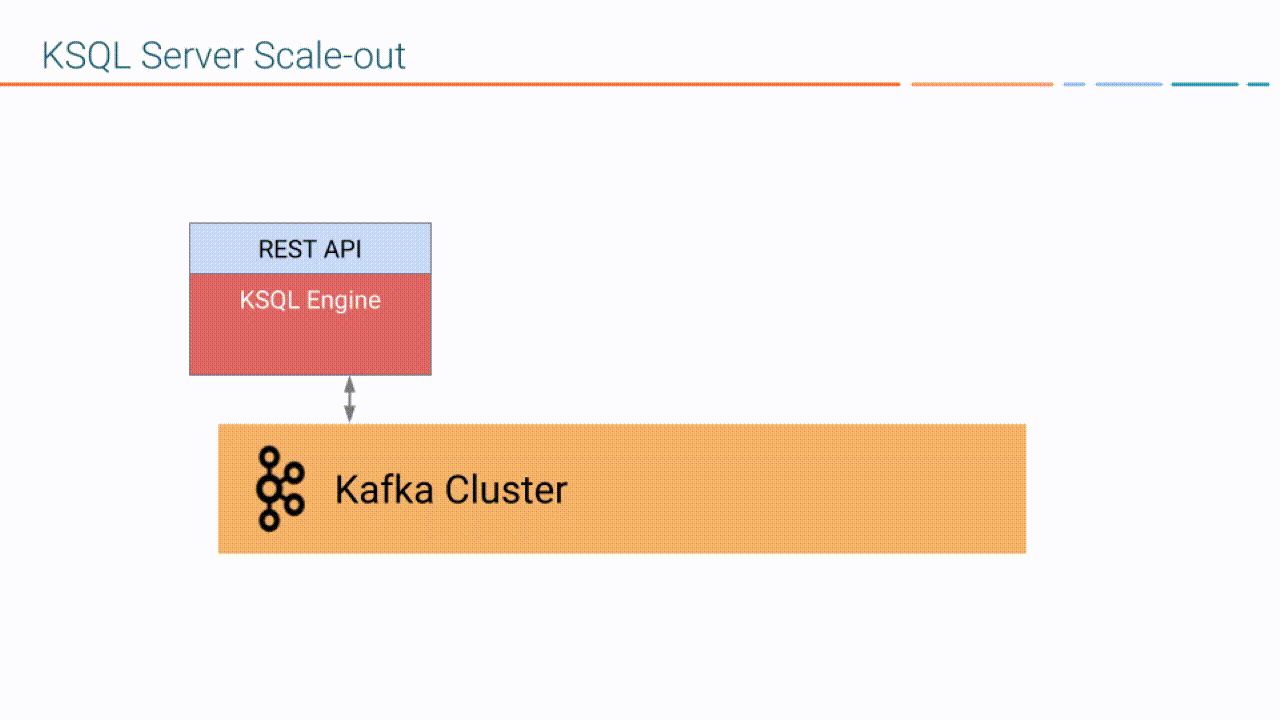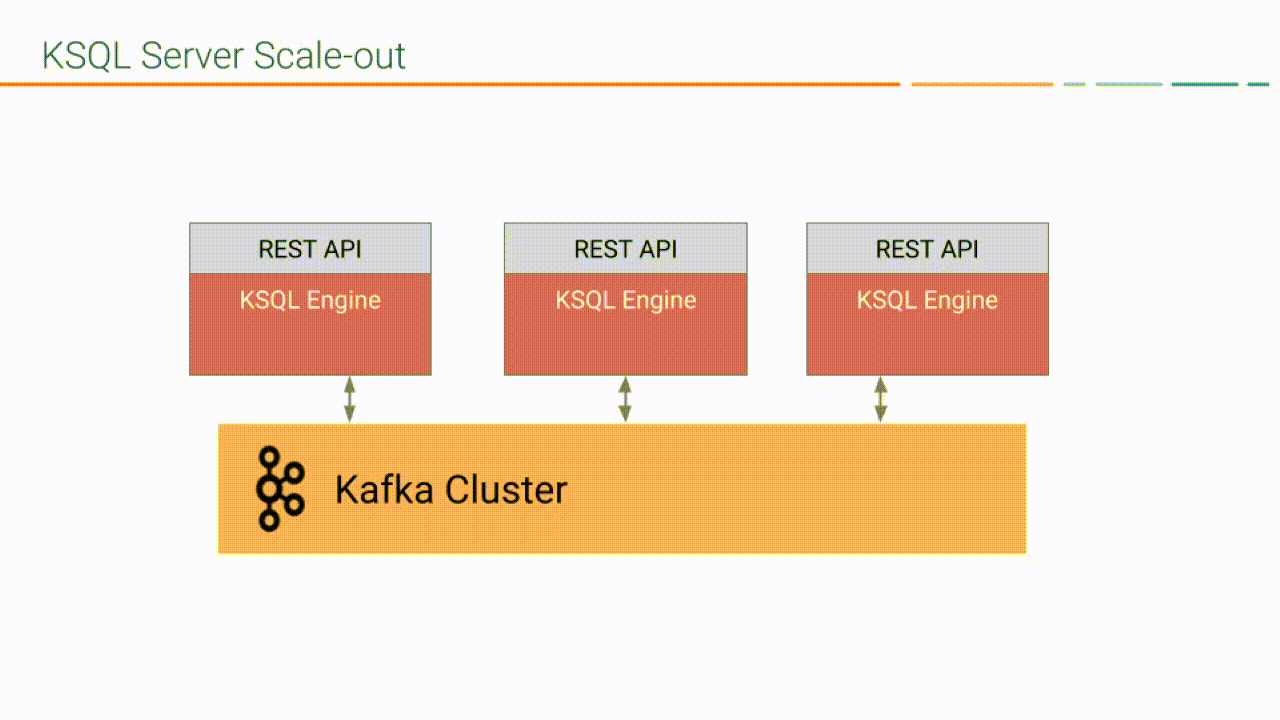
ksqlDB Server comprises the ksqlDB engine and the REST API. ksqlDB Server instances communicate with a Kafka cluster, and you can add more of them as necessary without restarting your applications.
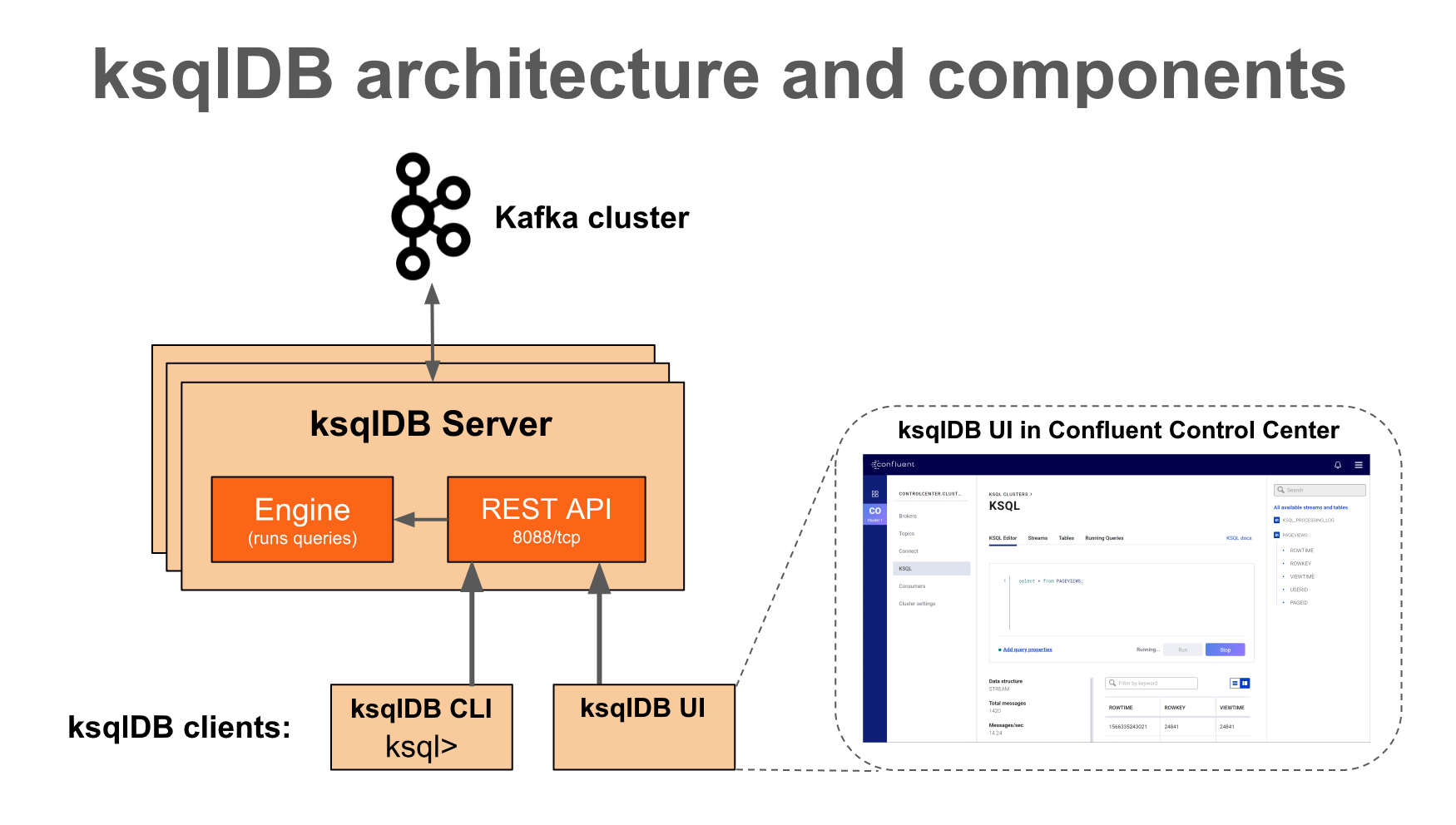
- ksqlDB Engine: The ksqlDB engine executes SQL statements and queries. You define your application logic by writing SQL statements, and the engine builds and runs the application on available ksqlDB servers. Each ksqlDB Server instance runs a ksqlDB engine. Under the hood, the engine parses your SQL statements and builds corresponding Kafka Streams topologies. The ksqlDB engine is implemented in the KsqlEngine.java class.
- ksqlDB CLI: The ksqlDB CLI provides a console with a command-line interface for the ksqlDB engine. Use the ksqlDB CLI to interact with ksqlDB Server instances and develop your streaming applications. The ksqlDB CLI is designed to be familiar to users of MySQL, Postgres, and similar applications. The ksqlDB CLI is implemented in the io.confluent.ksql.cli package.
- REST Interface: The REST server interface enables communicating with the ksqlDB engine from the CLI, Confluent Control Center, or from any other REST client. For more information, see ksqlDB REST API Reference. The ksqlDB REST server is implemented in the KsqlRestApplication.java class.
When you deploy your ksqlDB application, it runs on ksqlDB Server instances that are independent of one another, are fault-tolerant, and can be scaled with load. For more information, see ksqlDB Deployment Modes.
ksqlDB and Kafka Streams¶
ksqlDB is built on Kafka Streams, a robust stream processing framework that is part of Apache Kafka®. You can use ksqlDB and Kafka Streams together in your event streaming applications. For more information on their relationship, see ksqlDB and Kafka Streams. For more information on Kafka Streams, see Streams Architecture.
Also, you can implement custom logic and aggregations in your ksqlDB applications by implementing user defined functions (UDFs) in Java. For more information, see Custom Function Reference.
ksqlDB Language Elements¶
Like traditional relational databases, ksqlDB supports two categories of statements: Data Definition Language (DDL) and Data Manipulation Language (DML).
These categories are similar in syntax, data types, and expressions, but they have different functions in ksqlDB Server.
Data Definition Language (DDL) Statements¶
Imperative verbs that define metadata on the ksqlDB Server by adding, changing, or deleting streams and tables. Data Definition Language statements modify metadata only and don't operate on data. You can use these statements with declarative DML statements.
The DDL statements include:
- CREATE STREAM
- CREATE TABLE
- DROP STREAM
- DROP TABLE
- CREATE STREAM AS SELECT (CSAS)
- CREATE TABLE AS SELECT (CTAS)
Data Manipulation Language (DML) Statements¶
Declarative verbs that read and modify data in ksqlDB streams and tables. Data Manipulation Language statements modify data only and don't change metadata. The ksqlDB engine compiles DML statements into Kafka Streams applications, which run on a Kafka cluster like any other Kafka Streams application.
The DML statements include:
- SELECT
- INSERT INTO
- INSERT INTO VALUES
- CREATE STREAM AS SELECT (CSAS)
- CREATE TABLE AS SELECT (CTAS)
The CSAS and CTAS statements occupy both categories, because they perform both a metadata change, like adding a stream, and they manipulate data, by creating a derivative of existing records.
For more information, see ksqlDB Syntax Reference.
ksqlDB Deployment Modes¶
You can use deploy your ksqlDB streaming applications using either Interactive or Headless mode. We recommend using interactive mode when possible.
In both deployment modes, ksqlDB enables distributing the processing load for your ksqlDB applications across all ksqlDB Server instances, and you can add more ksqlDB Server instances without restarting your applications.
Note
All servers that run in a ksqlDB cluster must use the same deployment mode.
Interactive Deployment¶
When you deploy a ksqlDB server in interactive mode, the REST interface is available for the ksqlDB CLI and Confluent Control Center to connect to. This allows you to add and remove persistent queries without restarting the servers.
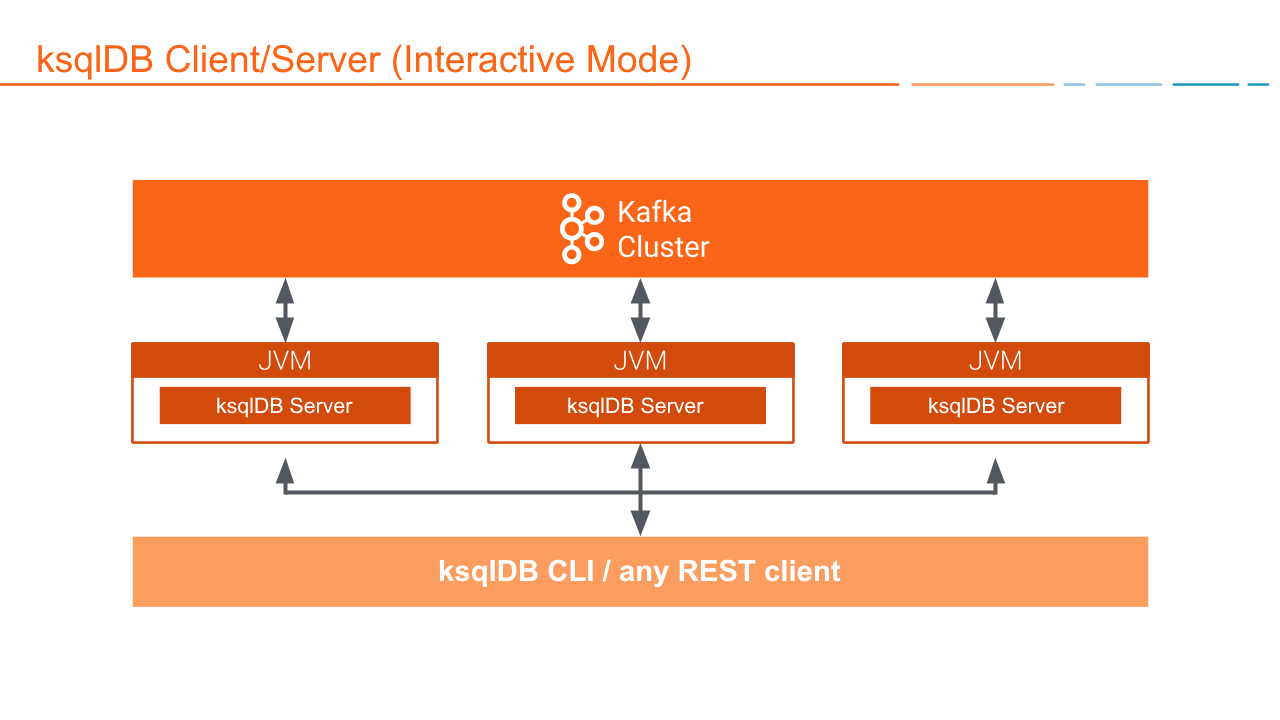
In interactive mode, you can:
- Write statements and queries on the fly
- Start any number of server nodes dynamically:
<path-to-confluent>/bin/ksql-server-start - Start one or more CLIs or REST Clients and point them to a server:
<path-to-confluent>/bin/ksql https://<ksql-server-ip-address>:8090
Command Topic¶
In interactive mode, ksqlDB shares statements with servers in the cluster
over the command topic. The command topic stores every SQL statement,
along with some metadata that ensures the statements are built
compatibly across ksqlDB restarts and upgrades. ksqlDB names the command
topic _confluent-ksql-<service id>command_topic, where <service id>
is the value in the ksql.service.id property.
By convention, the ksql.service.id property should end with a
separator character of some form, for example a dash or underscore, as
this makes the topic name easier to read.
Headless Deployment¶
When you deploy a ksqlDB Server in headless mode, the REST interface isn't available, so you assign workloads to ksqlDB clusters by using a SQL file. This can be useful if you want to completely lock down the set of persistent queries that ksqlDB will run. The SQL file contains the SQL statements and queries that define your application.
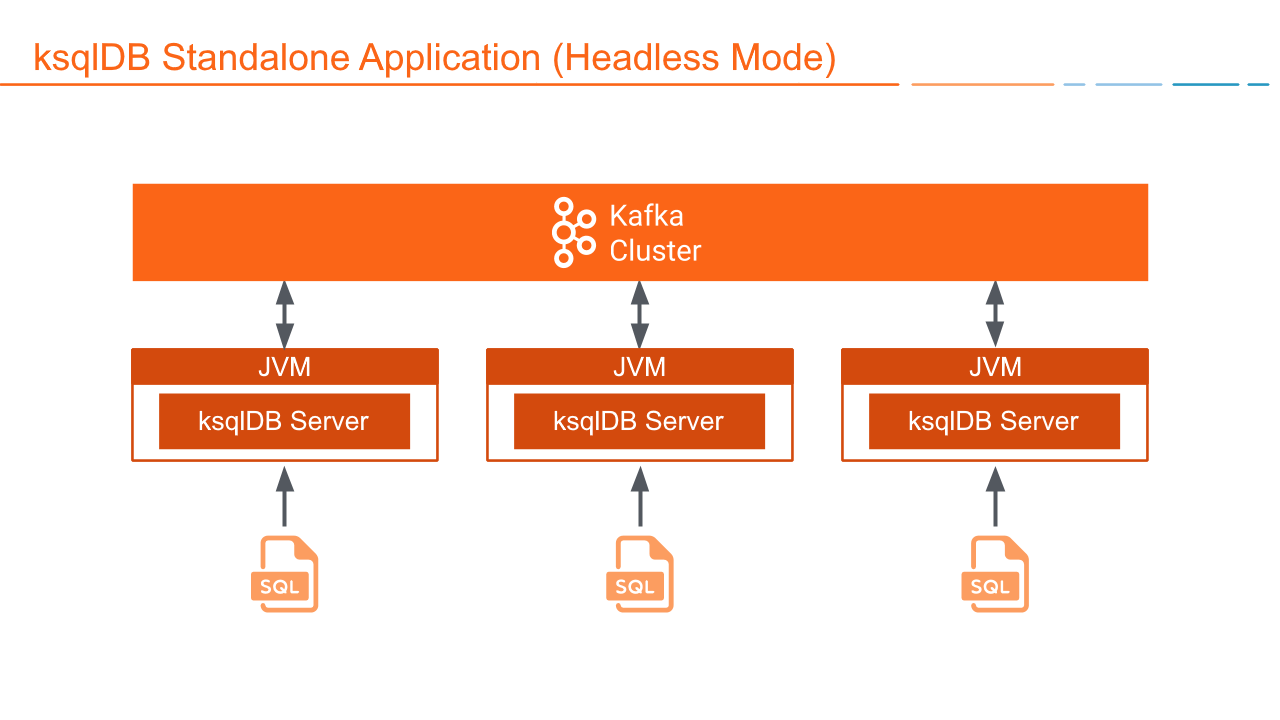
In headless mode you can:
- Start any number of server nodes
- Pass a SQL file with SQL statements to execute:
<path-to-confluent>bin/ksql-node query-file=path/to/myquery.sql - Ensure resource isolation
- Leave resource management to dedicated systems, like Kubernetes
Note
Headless mode deployments don't have a command topic.
Config Topic¶
In headless mode, you supply SQL statements to each server in its SQL
file. But ksqlDB still needs to store some internal metadata to ensure
that it builds queries compatibly across restarts and upgrades. ksqlDB
stores this metadata in an internal topic called the config topic.
ksqlDB names the config topic _confluent-ksql-<service id>_configs,
where <service id> is the value in the ksql.service.id property.
Supported Operations in Headless and Interactive Modes¶
The following table shows which SQL operations are supported in headless and interactive deployments.
| SQL Operation | Interactive ksqlDB | Headless ksqlDB |
|---|---|---|
| Describe a stream or table, including runtime stats (DESCRIBE, DESCRIBE EXTENDED) | Supported | Not Supported |
| Explain a query, including runtime stats (EXPLAIN) | Supported | Not Supported |
| CREATE a stream or table | Supported | Supported |
| DROP a stream or table | Supported | Not Supported |
| List existing streams and tables (SHOW STREAMS, SHOW TABLES) | Supported | Not Supported |
| List running queries (SHOW QUERIES) | Supported | Not Supported |
| Run a script (RUN SCRIPT) | Supported | Not Supported |
| Set query properties (SET) | Supported | Supported |
| Show contents of a Kafka topic (PRINT) | Supported | Not Supported |
| Show contents of a stream or table (SELECT) | Supported | Not Supported |
| Show properties of a query (SHOW PROPERTIES) | Supported | Not Supported |
| Show results of a query (SELECT) | Supported | Not Supported |
| TERMINATE a query | Supported | Not Supported |
| Start and stop a ksqlDB Server instance | Not with ksqlDB API | Not with ksqlDB API |
| Cleanup and delete internal data (internal topics) of a ksqlDB cluster or application | Supported (ksqlDB REST API) | Not with ksqlDB API |
Note
You can perform operations listed as "Not with ksqlDB API" manually.
Also, you can use deployment tools, like Kubernetes or Ansible, and you
can use the Kafka tools, like kafka-delete-records.
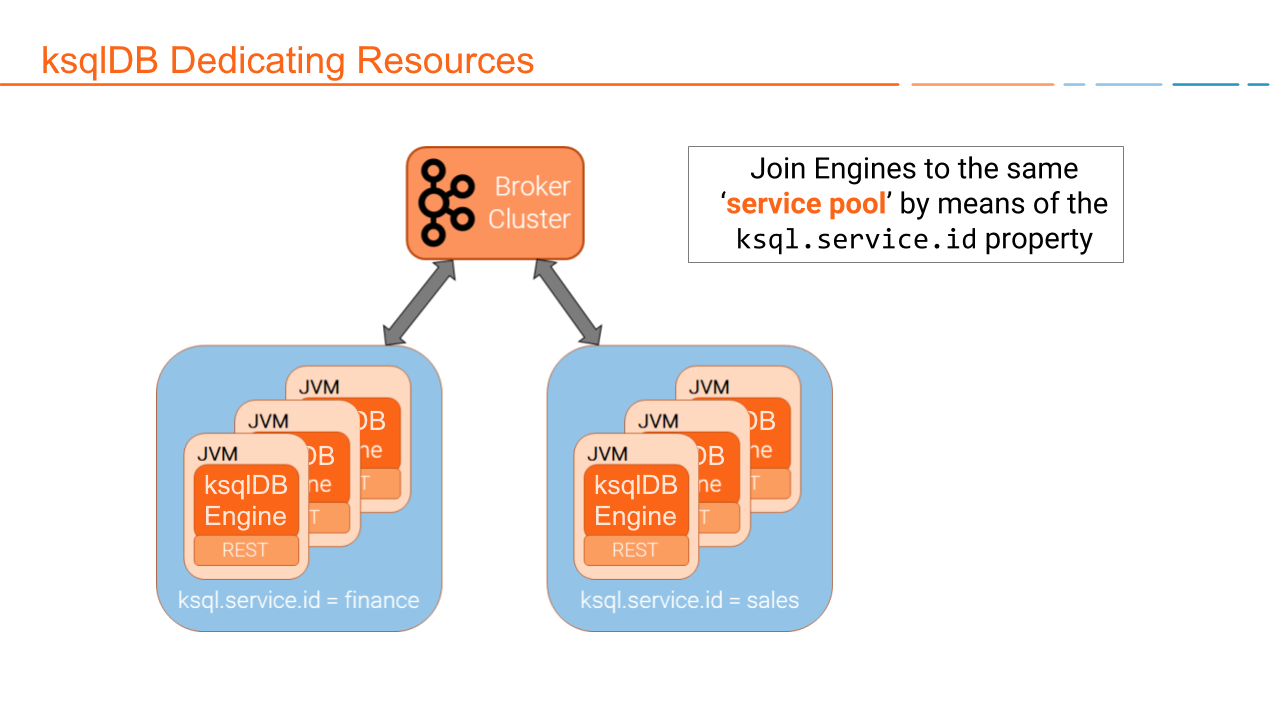
Dedicating Resources¶
Join ksqlDB engines to the same service pool by using the ksql.service.id
property. The following diagram shows a Kafka cluster with separate
workloads for a finance pool and a sales pool. For more information, see
ksql.service.id.
To scale out, just add more ksqlDB server instances. There's no master node or coordination among them required. For more information, see Capacity Planning.
ksqlDB Query Lifecycle¶
To create a streaming application with ksqlDB, you write SQL statements and queries. Each statement and query has a lifecycle with the following steps:
- You
register a ksqlDB stream or table
from an existing Kafka topic with a DDL statement, like
CREATE STREAM <my-stream> WITH <topic-name>. - You
express your app
by using a SQL statement, like
CREATE TABLE AS SELECT FROM <my-stream>. - ksqlDB parses your statement into an abstract syntax tree (AST).
- ksqlDB uses the AST and creates the logical plan for your statement.
- ksqlDB uses the logical plan and creates the physical plan for your statement.
- ksqlDB generates and runs the Kafka Streams application.
- You manage the application as a STREAM or TABLE with its corresponding persistent query.
Register the Stream¶
Register a stream or table by using the DDL statements, CREATE STREAM
and CREATE TABLE. For example, the following SQL statement creates a
stream named authorization_attempts that's backed by a topic named
authorizations.
1 2 3 | |
ksqlDB writes DDL and DML statements to the command topic. Each ksqlDB Server reads the statement from the command topic, parsing and analyzing it.
The CREATE STREAM statement is a DDL statement, so the action is to update the ksqlDB metadata.
Each ksqlDB Server has an internal, in-memory metadata store, or metastore, that it builds as it receives DDL statements. The metastore is an in-memory map. For each new DDL statement, the ksqlDB engine adds an entry to the metastore.
For example, the metastore entry for the previous CREATE STREAM statement might resemble:
| Source Name | Structured Data Source | |
|---|---|---|
| AUTHORIZATION_ATTEMPTS | [DataSourceType: STREAM], [Schema:(card_number VARCHAR, attemptTime BIGINT, attemptRegion VARCHAR, ...)], [Key: null], [KsqlTopic: AUTHORIZATIONS], ... | |
The ksqlDB metastore is implemented in the io.confluent.ksql.metastore package.
Express Your Application as a SQL Statement¶
Now that you have a stream, express your application's business logic
by using a SQL statement. The following DML statement creates a
possible_fraud table from the authorization_attempts stream:
1 2 3 4 5 6 7 8 | |
The ksqlDB engine translates the DML statement into a Kafka Streams
application. The application reads the source topic continuously, and
whenever the count(*) > 3 condition is met, it writes records to the
possible_fraud table.
ksqlDB Parses Your Statement¶
To express your DML statement as a Kafka Streams application, the ksqlDB engine starts by parsing the statement. The parser creates an abstract syntax tree (AST). The ksqlDB engine uses the AST to plan the query.
The SQL statement parser is based on ANTLR and is implemented in the io.confluent.ksql.parser package.
ksqlDB Creates the Logical Plan¶
The ksqlDB engine creates the logical plan for the query by using the AST.
For the previous possible_fraud statement, the logical plan has the
following steps:
- Define the source -- FROM node
- Apply the filter -- WHERE clause
- Apply aggregation -- GROUP BY
- Project -- WINDOW
- Apply post-aggregation filter -- HAVING, applied to the result of GROUP BY
- Project -- for the result

ksqlDB Creates the Physical Plan¶
From the logical plan, the ksqlDB engine creates the physical plan, which is a Kafka Streams DSL application with a schema.
The generated code is based on the ksqlDB classes, SchemaKStream and
SchemaKTable:
- A ksqlDB stream is rendered as a SchemaKStream instance, which is a KStream with a Schema.
- A ksqlDB table is rendered as a SchemaKTable instance, which is a KTable with a Schema.
- Schema awareness is provided by the SchemaRegistryClient class.
The ksqlDB engine traverses the nodes of the logical plan and emits corresponding Kafka Streams API calls:
- Define the source -- a
SchemaKStreamorSchemaKTablewith info from the ksqlDB metastore - Filter -- produces another
SchemaKStream - Project --
select()method - Apply aggregation -- Multiple steps:
rekey(),groupby(), andaggregate()methods. ksqlDB may re-partition data if it's not keyed with a GROUP BY phrase. - Filter --
filter()method - Project --
select()method for the result
If the DML statement is CREATE STREAM AS SELECT or CREATE TABLE AS SELECT, the result from the generated Kafka Streams application is a persistent query that writes continuously to its output topic until the query is terminated.